

The recent deep dive into the IDEs of the DOS times 30 years ago made me reminisce of DJGPP, a distribution of the GNU development tools for DOS.
I remember using DJGPP back in the 1990s before I had been exposed to Linux and feeling that it was a strange beast. Compared to the Microsoft C Compiler and Turbo C++, the tooling was bloated and alien to DOS, and the resulting binaries were huge. But DJGPP provided a complete development environment for free, which I got from a monthly magazine, and I could even look at its source code if I wished. You can’t imagine what a big deal that was at the time.
But even if I could look under the cover, I never did. I never really understood why was DJGPP so strange, slow, and huge, or why it even existed. Until now. As I’m in the mood of looking back, I’ve spent the last couple of months figuring out what the foundations of this software were and how it actually worked. Part of this research has resulted in the previous two posts on DOS memory management. And part of this research is this article. Let’s take a look!
Special thanks go to DJ Delorie himself for reviewing a draft of this article. Make sure to visit his website for DJGPP and a lot more cool stuff!
What is DJGPP?
Simply put, DJGPP is a port of the GNU development tools to DOS. You would think that this was an easy feat to achieve given that other compilers did exist for DOS. However… you should know that Richard Stallman (RMS)—the creator of GNU and GCC—thought that GCC, a 32-bit compiler, was too big to run on a 16-bit operating system restricted to 1 MB of memory. DJ Delorie took this as a challenge in 1989 and, with all the contortions that we shall see below, made GCC and other tools like GDB and Emacs work on DOS.
To a DOS and Windows user, DJGPP was, and still is, an alien development environment: the tools’ behavior is strange compared to other DOS compilers, and that’s primarily due to their Unix heritage. For example, as soon as you start using DJGPP, you realize that flags are prefixed by a dash instead of a slash, paths use forward slashes instead of backward slashes, and the files don’t ship in a flat directory structure like most other programs did. But hey, all the tools worked and, best of all, they were free!
In fact, from reading about the historical goals of the project, I gather that a secondary goal was for DJ to evangelize free software to as many people as possible, meeting them where they already were: PC users with a not-very-powerful machine that ran DOS. Mind you, this plan worked on some of us as we ended up moving to Linux and the free software movement later on.
In any case, being a free alien development environment doesn’t explain why it had to be huge and slow compared to other others. To explain this, we need to look at the “32-bit compiler” part.
DOS and hardware constraints
As we saw in a previous article, Intel PCs based on the 80386 have two main modes of operation: real mode and protected mode. In real mode, the processor behaves like a fast 16-bit 8086, limiting programs to a 1 MB address space and with free reign to access memory and hardware peripherals. In protected mode, programs are 32-bit, have access to a 4 GB address space, and there are protection rules in place to access memory and hardware.
DOS was a 16-bit operating system that ran in real mode. Applications that ran on DOS leveraged DOS’ services for things like disk access, were limited to addressing 1 MB of memory, and had complete control of the computer. Contrary to that, GCC was a 32-bit program that had been designed to run on Unix (oops sorry, GNU is Not Unix) and produce binaries for Unix, and Unix required virtual memory from the ground up to support multiprocessing. (I know that’s not totally accurate but it’s easier to think about it that way.)
Intel-native compilers for DOS, such as the Microsoft C compiler and Turbo C++, targeted the 8086’s weird segmented architecture and generated code accordingly. Those compilers had to deal with short, near, and far jumps—which is to say I have extra research to do and write another article on ancient DOS memory models. GCC, on the other hand, assumes the full address space is available to programs and generates code making such assumptions.
A blog on operating systems, programming languages, testing, build systems, my own software projects and even personal productivity. Specifics include FreeBSD, Linux, Rust, Bazel and EndBASIC.
![]()
![]()
![]()
GCC was not only a 32-bit program, though: it was also big. In order to compile itself and other programs, GCC needed more physical memory than PCs had back then. This means that, in order to port GCC to DOS, GCC needed virtual memory. In turn, this means that GCC had to run in protected mode. Yet… DOS is a real mode operating system, and calling into DOS services to access files and the like requires the processor to be in real mode.
To address this conundrum, DJ had to find a way to make GCC and the programs it compiles integrate with DOS. After all, if you have a C program that opens a file and you compile said program with GCC, you want the program to open the file via the DOS file system for interoperability reasons.
Here, witness this. The following silly program, headself.c, goes out of its way to allocate a buffer above the 2 MB mark and then uses said buffer to read itself into it, printing the very first line of its source code:
#include <fcntl.h>
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define BUFMINBASE 2 * 1024 * 1024
#define BUFSIZE 1 * 1024 * 1024
int main(void) {
// Allocate a buffer until its base address is past the 2MB boundary.
char* buf = NULL;
while (buf < (char*)(BUFMINBASE))
buf = (char*)malloc(BUFSIZE);
printf("Read buffer base is at %zd KB\n", ((intptr_t)buf) / 1024);
// Open this source file and print its first line. Really unsafe.
int fd = open("headself.c", O_RDONLY);
read(fd, buf, BUFSIZE);
char *ptr = buf; while (*ptr != '\n') ptr++; *(ptr + 1) = '\0';
printf("%s", buf);
return EXIT_SUCCESS;
}
Yes, yes, I know the above code is really unsafe and lacks error handling throughout. But that’s not important here. Watch out what happens when we compile and run this program with DJGPP on DOS:

Note two things. The first is that the program has to have run in protected mode because it successfully allocated a buffer above the 1 MB mark and used it without extraneous API calls. The second is that the program is invoking file operations, and those operations interact with files managed by DOS.
And here is where the really cool stuff begins. On the one hand, we have DOS as a real mode operating system. On the other hand, we have programs that want to interoperate with DOS but they also want to take advantage of protected mode to leverage the larger address space and virtual memory. Unfortunately, protected mode cannot call DOS services because those require real mode.
The accepted solution to this issue is the use of a DOS Extender as we already saw in the previous article but such technology was in its infancy. DJ actually went through three different iterations to fully resolve this problem in DJGPP:
- The first prototype used Phar Lap’s DOS Extender but it didn’t get very far because it didn’t support virtual memory.
- Then, the first real version of DJGPP used DJ’s own DOS Extender called go32, a big hack that I’m not going to talk about here.
- And then, the second major version of DJGPP—almost a full rewrite of the first one—switched to using the DOS Protected Mode Interface (DPMI).
At this point, DJGPP was able to run inside existing DPMI hosts such as Windows or the many memory managers that already existed for DOS and it didn’t have to carry the hacks that previously existed in go32 (although the go32 code went on to live inside CWSDPMI). The remainder of this article only talks about the latter of these versions.
Large buffers
One thing you may have noticed in the code of the headself.c example above is that I’m using a buffer for the file read that’s 1 MB-long. That’s not unintentional: for such a large buffer to even exist (no matter our attempts to push it above 2 MBs), the buffer must be allocated in extended memory. But if it is allocated in extended memory, how can the file read operations that we send to DOS actually address such memory? After all, even if we used unreal mode, the DOS APIs wouldn’t understand it.
The answer is the transfer buffer. The transfer buffer is a small and static piece of memory that DJGPP-built programs allocate at startup time below the 1 MB mark. With that in mind, and taking a file read as an example, DJGPP’s C library does something akin to the following:
- The protected-mode
readstub starts executing. - The stub issues a DPMI read call (which is to say, it executes the DOS read file API but uses the DPMI trampoline) onto the transfer buffer.
- The DPMI host switches to real mode and calls the DOS read file API.
- The real-mode DOS read places the data in the transfer buffer.
- The real-mode DPMI host switches back to protected mode and returns control to the protected-mode stub.
- The protected-mode
readstub copies the data from the transfer buffer into the user-supplied buffer.
This is all good and dandy but… take a close look at DOS’s file read API:
Request:
INT 21h
AH -> 3Fh
BX -> file handle
CX -> number of bytes to read
DS:DX -> buffer for data
Return:
CF -> clear if successful
AX -> number of bytes actually read (0 if at EOF before call)
CF -> set on error
AX -> error code (05h,06h) (see #01680 at AH=59h/BX=0000h)
That’s right: file read and write operations are restricted to 64 KB at a time because the number of bytes to process is specified in the 16-bit CX register. Which means that, in order to perform large file operations, we need to go through the dance above multiple times in a loop. And that’s why DJGPP is slow: if the DPMI host has to switch to real mode and back for every system call, the overhead of each system call is significant.
Now is a good time to take a short break and peek into DJGPP’s read implementation. It’s succinct and clearly illustrates what I described just above. And with that done, let’s switch gears.
Globs without a Unix shell
Leveraging protected mode and a large memory address space are just two important but small parts of the DJGPP puzzle. The other interesting pieces of DJGPP are those that make Unix programs run semi-seamlessly on DOS, and there are many such pieces. I won’t cover them all here because Eli Zarateskii’s presentation did an excellent job at that. So want I to do instead is look at a subset of them apart and show them in action.
To begin, let’s try to answer this question: how do you interact with a program originally designed for Unix on a DOS system? The Unix shell is a big part of such interaction and COMMAND.COM is no Unix shell. To summarize the linked article: the API to invoke an executable on Unix takes a list of arguments while on DOS and Windows it takes a flat string. Partially because of this, the Unix shell is responsible for expanding globs and dealing with quotation characters, while on DOS and Windows each program is responsible for tokenizing the command line.
Leaving aside the fact that the DOS API is… ehem… bad, this fundamental difference means that any Unix program ported to DOS has a usability problem: you cannot use globs anymore when invoking it! Something as simple and common as gcc -o program.exe *.c would just not work. So then… how can we explain the following output from the showargs.c program, a little piece of code that prints argv?
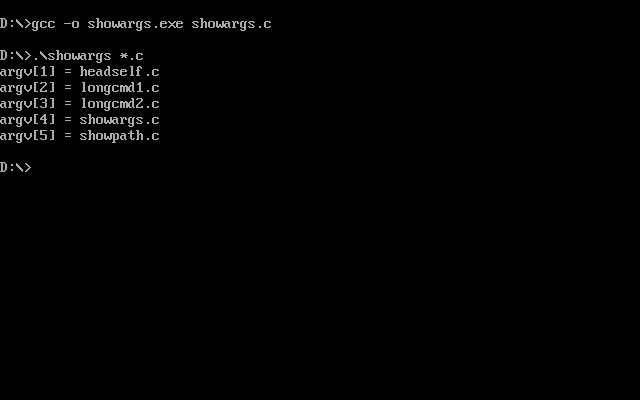
In the picture above, you can see how I ran the showargs.c program with *.c as its own argument and somehow it worked as you would expect. But if we build it with a standard DOS compiler we get different results:
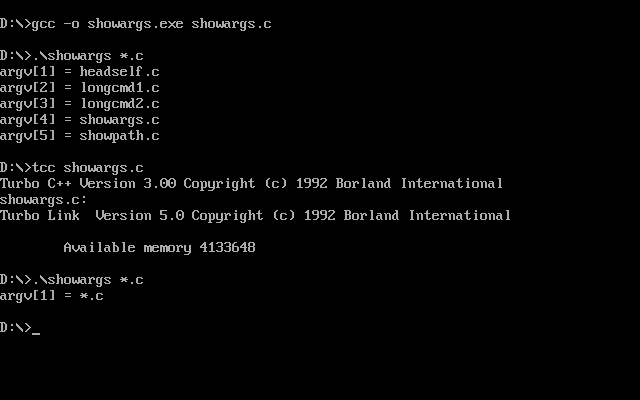
GCC is actually doing something to make glob expansion work—and it has to, because remember that DJGPP was not just about porting GCC: it was about porting many more GNU developer tools to DOS. Having had to patch them one by one to work with DOS’ COMMAND.COM semantics would have been a sad state of affairs.
To understand what’s happening here, know that all C programs compiled by any compiler include a prelude: main is not the program’s true entry point. All compilers wrap main with some code of their own to set up the process and the C library, and DJGPP is no different. Such code is often known as the crt (or C Runtime) and it comes in two phases: crt0, written in assembly for early bootstrapping, and crt1, written in C.
As you can imagine, this is where the magic lives. DJGPP’s crt1 is in charge of processing the flat command line that it receives from DOS and transforming it into the argv that POSIX C programs expect, following common Unix semantics. In a way, this code performs the job of a Unix shell.
Once again, take a break to inspect the crt0 sources and, in particular, the contents of the c1args.c file. Pay attention to file reads and the “proxy” thing, both of which bring us to the next section.
Long command lines
Unix command lines aren’t different just because of glob expansion. They are also different because they are usually long, and they are long in part because of glob expansion and in part because Unix has supported long file names for much longer than DOS.
Unfortunately… DOS restricted command lines to a maximum of 126 characters—fewer characters than you can fit in a Tweet or an SMS—and this posed a problem because the build process of most GNU developer tools, if not all, required using long command lines. To resolve these issues, DJGPP provides two features.
The first is support for response files. Response files are text files that contain the full command line. These files are then passed to a process with the @file.txt syntax, which then causes DJGPP’s crt1 code to load the response files and construct the long command line in extended memory.
Let’s take a look. If we reuse our previous showargs.c program that prints the command line arguments, we can observe how the behavior differs between building this program with a standard DOS compiler and with DJGPP:
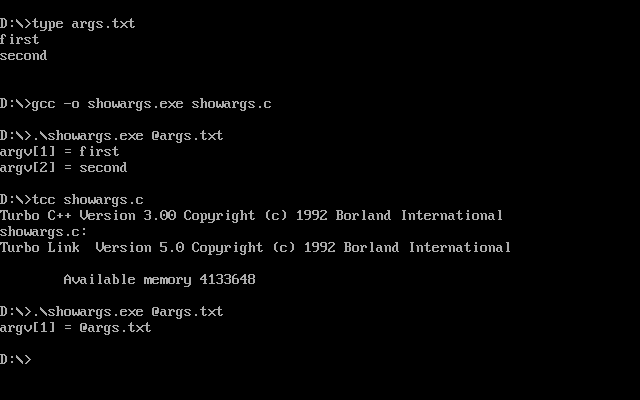
Response files are easy to implement and they are sufficient to support long command lines: even if they require special handling on the caller side to write the arguments to disk and then place the response file as an argument, this could all be hidden inside the exec family of system calls. Unfortunately, using response files is slow because, in order to invoke a program, you need to write the command line to a file—only to load it immediately afterwards. And disk I/O used to be really slow.
For this reason, DJGPP provides a different mechanism to pass long command lines around, and this is via the transfer buffer described earlier. This mechanism involves putting the command line in the transfer buffer and telling the executed command where its command line lives. This mechanism obviously only works when executing a DJGPP program from another DJGPP program, because no matter what, process executions are still routed through DOS and thus are bound by DOS’ 126 character limit.
Let’s try this too. For this experiment, we’ll play with two programs: one that prints the length of the received command line and another one that produces a long command line and executes the former.
The first program is longcmd1.c and is depicted below. All this program does is allocate a command line longer than DOS’ maximum length of 126 characters and, once it has built the command line, invokes longcmd2.exe with said long command line:
#ifdef __GNUC__
#include <unistd.h>
#else
#include <process.h>
#endif
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char** argv) {
char** longcmd;
int i;
// Generate a command line that exceeds DOS' limits.
longcmd = (char**)malloc(32);
longcmd[0] = argv[0];
for (i = 1; i < 31; i++) {
longcmd[i] = strdup("one-argument");
}
longcmd[i] = NULL;
// Execute the second stage of this demo to print the received
// command line.
if (execv(".\\longcmd2.exe", longcmd) == -1) {
perror("execv failed");
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
The second program is longcmd2.c and is depicted below. This program prints the number of arguments it received and also computes the length of the command line (assuming all arguments were separated by just one space character):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char** argv) {
int i;
int total;
total = 0;
for (i = 0; i < argc; i++) {
if (i > 0) {
total += 1; // Assume 1 space between arguments.
}
total += strlen(argv[i]);
}
printf("argc after re-exec: %d\n", argc);
printf("textual length: %d\n", total);
return EXIT_SUCCESS;
}
Now let’s see what happens when we compile these two programs with Turbo C++ and with DJGPP. First, let’s build both with Turbo C++ and run the longcmd1.exe entry point:
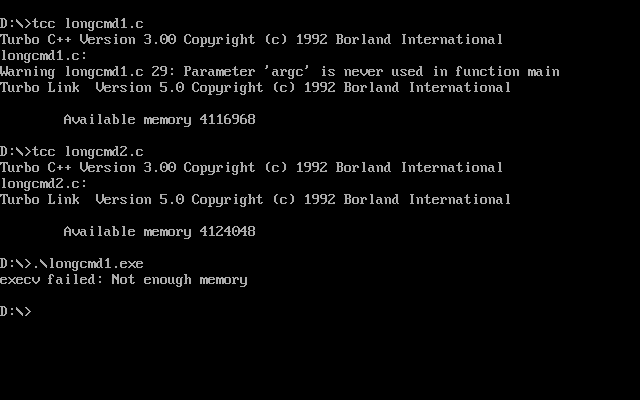
Running longcmd1.exe fails because the command line is too long and execv cannot process it. (I’m not exactly sure why execv returns ENOMEM because the Turbo C++ documentation claims that this function should return E2BIG on this condition, but alas.)
Now, let’s build just longcmd1.c with DJGPP and run it:
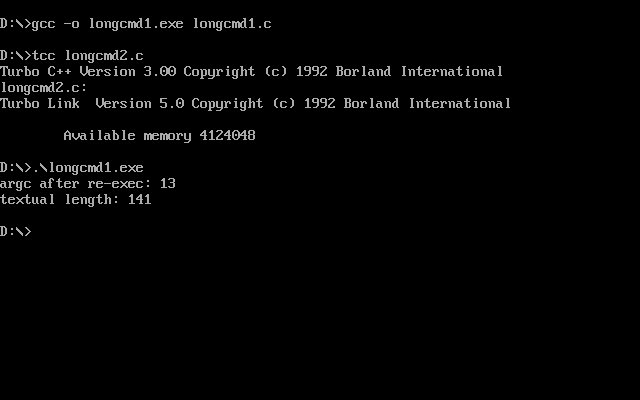
We get a bit further now! longcmd1.exe runs successfully and executes longcmd2.exe… but longcmd2.exe claims that the command line is shorter than we expect. This is because DJGPP’s execv implementation knew that it was running a standard DOS application not built by DJGPP, so it had to place a truncated command line in the system call issued to DOS. (As a detail also note that this shows 141 and not 126: the reason for this is that DOS does not place argv[0] on the command line, but the C runtime has to synthesize this value.)
But now look at what happens when we also compile longcmd2.c with DJGPP:
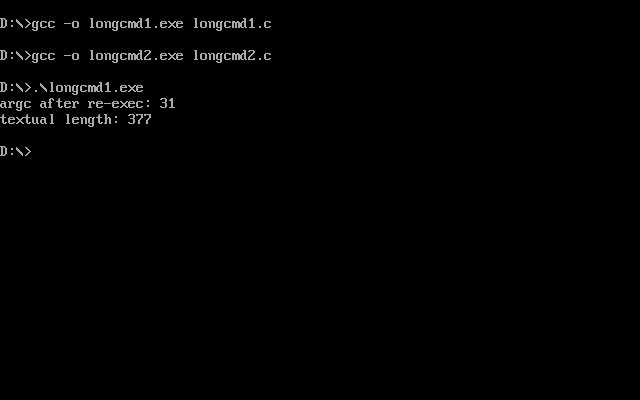
Ta-da! When longcmd2.exe runs, it now sees the full command line. This is because longcmd1.exe now knows that longcmd2.exe understands the transfer buffer arrangement and can send the command line to it this way.
You can read more about this in the spawn documentation from DJGPP’s libc and peek at the dosexec.c sources.
Unix-style paths
Let’s move on to one more Unix-y thing that DJGPP has to deal with, which is paths and file names. You see, paths are paths in both DOS and Unix: a sequence of directory names (like /usr/bin/) followed by an optional file name (like /usr/bin/gcc). Unfortunately, DOS and Unix paths differ in two aspects.
The first is that DOS paths separate directory components with a backslash, not a forward slash. This is a historical artifact of the early CP/M and DOS days, where command-line flags used the forward slash (DIR /P) instead of Unix’s dash (ls -l). When DOS gained support for directories in its 2.0 release, it had to pick a different character to separate directories, and it picked the backslash. Dealing with this duality in DJGPP-built programs seems easy: just make DJGPP’s libc functions allow both and call it a day. And for the most part, this works—and in fact even PowerShell does this on Windows today.
The second is that DOS paths may include an optional drive name such as C: and… the drive name has the colon character in it. While Unix uses the colon character to separate multiple components of the search PATH, DOS could not do that: it had to pick a different character, and it picked the semicolon. Take a look:
C:\>path
PATH=Z:\;C:\DEVEL\BIN;C:\DEVEL\DJGPP\BIN;C:\DEVEL\TC\BIN
The problem here is that many Unix applications, particularly shell scripts like configure—especially configure—read the value of the PATH variable and split it at colon separators or append to it by adding a colon. But if we do these textual manipulations on a DOS-style PATH like the one shown above… we’ll get the wrong behavior because of the drive names—and Unix programs don’t know they have to split on the semicolon instead and we cannot be expected to fix them all.
The way DJGPP deals with this is by faking the /dev/ device tree. While DJGPP provides implementations of things like /dev/null, it also exposes DOS drives via their corresponding /dev/[a-z]/ virtual directory. So, if you wanted to run applications that parse or modify the PATH, you could rewrite the above as this:
PATH=/dev/z:/dev/c/devel/bin:/dev/c/devel/djgpp/bin:/dev/c/devel/tc/bin
This would allow any application reading the PATH to continue to work. But note that this value doesn’t seem to leave the realm of the current process, which is interesting:

The picture above shows how bash sees a DOS-style PATH after it starts. Manually setting it to a Unix path keeps the Unix path in the current process (as shown by the built-in echo calls), but when we spawn a different one (env is a separate executable), the value is reset. This makes sense because, if we are running a regular DOS program from within a DJGPP one, we want to export a DOS-compatible environment. Which means the Unix variants probably only stick within shell scripts. You can also see how this works by peeking at dosexec.c again.
But wait a minute… did I just show you bash?! On DOS? Oh yes, yes I did…
Trying it out yourself
It’s time to get our hands dirty, try this out, and reminisce the old days! Or, actually, not so old. You should know that DJGPP is still available in this day and age and that it is quite up to date with GCC 12.3—released less than a year ago.
First off, start by installing DOSBox. You can use the standard DOSBox version, but it’s probably better to go the DOSBox-X route so that you can get Long File Name (LFN) support by setting the ver=7.1 configuration option. Otherwise, beware that running Bash later on will create .bash_history under C:\ but the file will be named .BAS due to some odd truncation, and this will later confuse Bash on a second start and assume that .BAS is actually .bash_login.
Now, pick a mirror for your downloads. You’ll see various uses of FTP in the list but don’t be surprised if clicking on those doesn’t work: major browsers have unfortunately dropped their FTP client so you’ll have to “fall back” to an HTTP mirror.
From there, you can use the Zip Picker to help you choose what you need or you can download the same files I did:
v2apps/csdpmi7b.zip: TheCWSDPMIfree DPMI host.v2apps/rhid15ab.zip: The RHIDE console IDE akin to Turbo C++.v2/djdev205.zip: Base DJGPP tools.v2gnu/bnu2351b.zip: GNU Binutils (tools likegasandobjdump).v2gnu/bsh4253b.zip: GNU Bash.v2gnu/em2802b.zip: GNU Emacs.v2gnu/fil41br3.zip: GNU coreutils (tools likelsandcp).v2gnu/gcc930b.zip: GCC itself.v2gnu/gdb801b.zip: GDB because why not.v2gnu/gpp930b.zip: G++.v2gnu/grep228b.zip: grep because I find it very handy.v2gnu/mak44b.zip: GNU Make.v2gnu/shl2011br3.zip: Various shell utilities (likebasenameanddirname) that you’ll almost-certainly need to run shell scripts.v2gnu/txt20br3.zip: GNU textutils (tools likecatandcut).
Once you have those files, create the “root” directory for what will be the C: drive in DOSBox. I keep this under ~/dos/ and it is much easier to prepare this directory from outside of DOSBox. Within that location, create a djgpp subdirectory and unpack all the zip files you downloaded into it. If there are any file conflicts, just tell unzip to overwrite them.
Once the unpacking finishes, go to your DOSBox configuration. If you are on Windows, you should have a start menu entry called “DOSBox 0.74-3 Options” or similar which opens the configuration file in Notepad. If you are on Linux or any other reasonable OS, you can find the configuration file under ~/.dosbox/. In the configuration, you’ll want to set up the C: drive at the very bottom of the file where the [autoexec] section is. Here is what I do:
[autoexec]
MOUNT C C:\Users\jmmv\dos
SET PATH=%PATH%;C:\DJGPP\BIN
SET DJGPP=C:\DJGPP\DJGPP.ENV
C:
Launch DOSBox and you are set. Enter full-screen by pressing Alt+Enter for the full retro experience and then… launch bash:
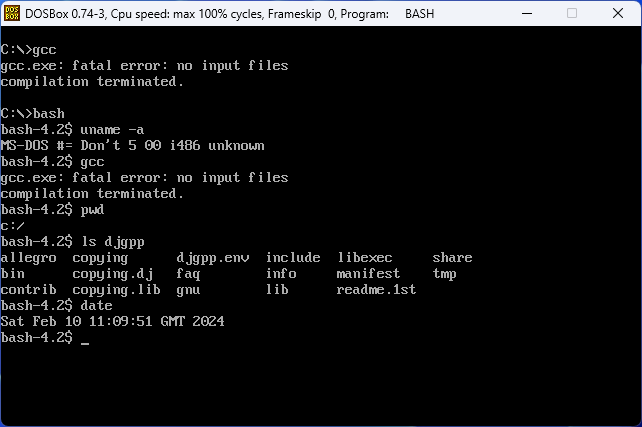
Pretty neat stuff, huh?


Featured software
Featured posts
- Fast machines, slow machines
- EndBASIC 0.10: Core language, evolved
- Farewell, Microsoft; hello, Snowflake!
- Rust is hard, yes, but does it matter?
- Rust traits and dependency injection
- A year on Windows: Introduction
- Always be quitting
- How does Google keep build times low?
- How does Google avoid clean builds?
- Unit-testing a console app (a text editor)
- More...